

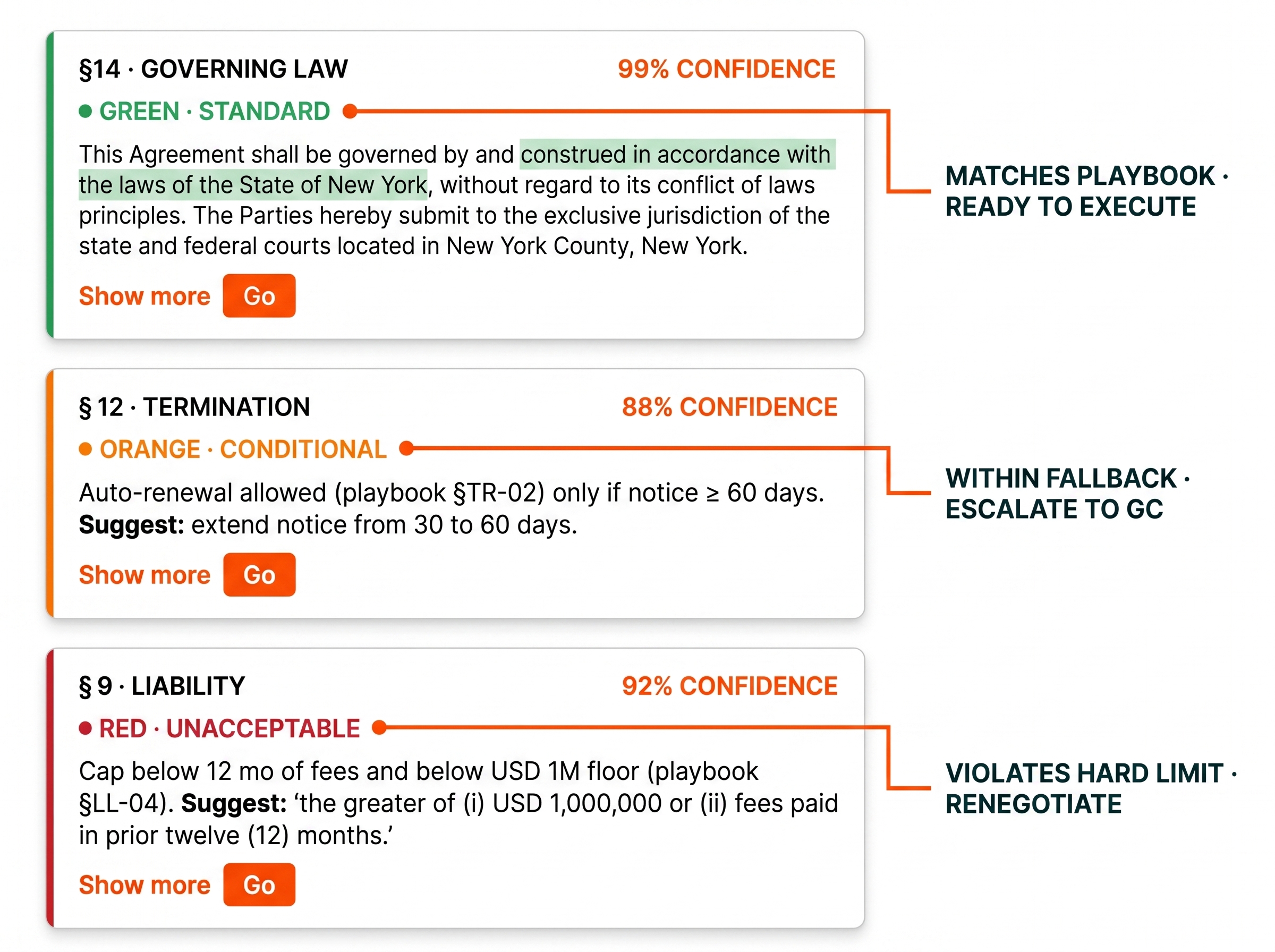
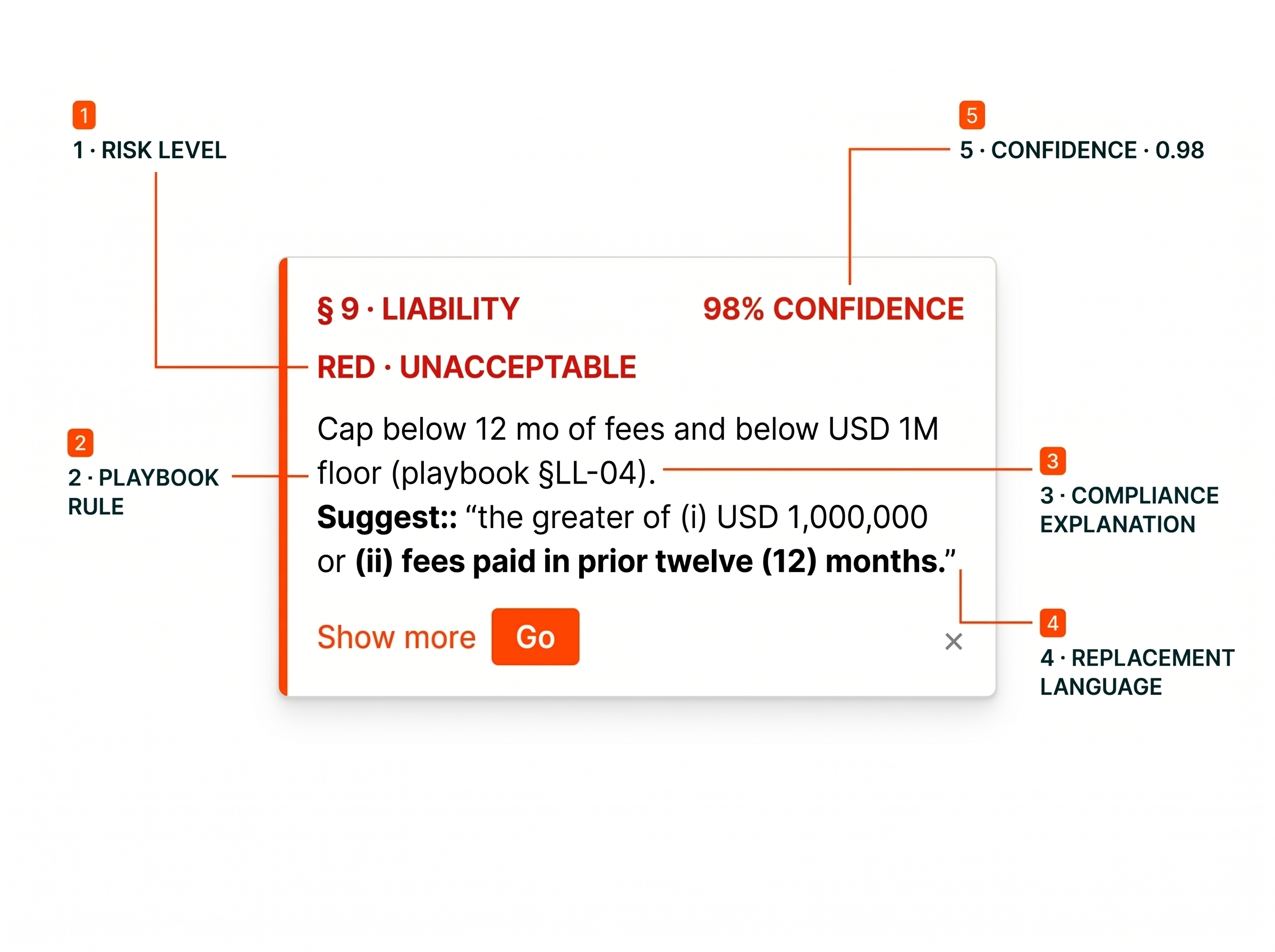
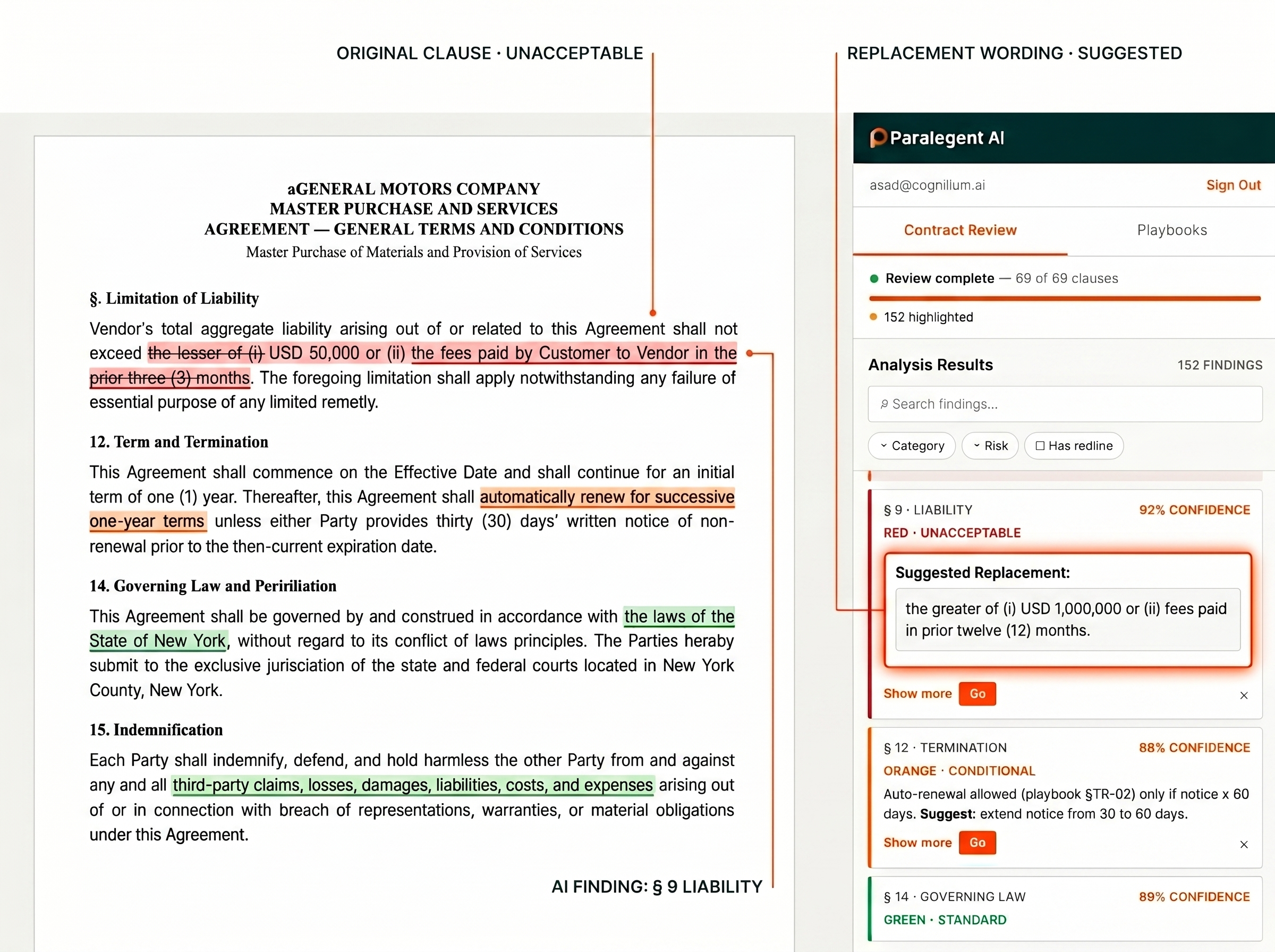
Payment Terms — Net 60 Days
Buyer shall pay all undisputed invoices within sixty (60) days of receipt of a valid invoice.
Rationale
Matches Playbook Term 2.1: Payment Terms. Net 60 days falls within the preferred range of Net 30-60.
→ No action required — clause is ready for execution.


